Intro to Genomics Data Wrangling
Berkeley Institute for Data Science
August 6-7, 2018
9:15 am - 5:30 pm
Instructors: Caroline Cypranowska, Diya Das
Helpers: Jenna Baughman, Drew Hart, Dennis Sun
Registration
This workshop is one of three workshops offered at BIDS. Please register for only one, as space is limited.
Registration is mandatory for attendance. We are unable to accept participants who do not have a ticket from Eventbrite (i.e. no drop-ins).
General Information
Data Carpentry aims to help researchers get their work done in less time and with less pain by teaching them basic research computing skills. This hands-on workshop will cover basic concepts and tools, including program design, version control, data management, and task automation. Participants will be encouraged to help one another and to apply what they have learned to their own research problems.
For more information on what we teach and why, please see our paper "Best Practices for Scientific Computing".
Who: The course is aimed at graduate students and other researchers at UC Berkeley. Participants from outside the university are welcome to join as long as the Eventbrite permits, for reasons of capacity. However, there is a slight chance that the cloud computing session may not be accessible to you, as it focuses on resources made available by Berkeley Research Computing.
The workshop material is presented at an introductory level, and we will assume that you will not have any previous knowledge of the tools that will be presented at the workshop. The goal of the workshop is to provide learners new to these tools with a basis for further exploration. If you are already familiar with some of these tools, we instead encourage you to check out our peer learning group.
Where: 190 Doe Library, University of California, Berkeley. Get directions with OpenStreetMap or Google Maps.
When: August 6-7, 2018. Add to your Google Calendar.
Requirements: Participants must bring a laptop with a Mac, Linux, or Windows operating system (not a tablet, Chromebook, etc.) that they have administrative privileges on. They should have a few specific software packages installed (listed below). They are also required to abide by Data Carpentry's Code of Conduct.
Accessibility: We are committed to making this workshop accessible to everybody. The workshop organizers have checked that:
- The room is wheelchair / scooter accessible.
- Accessible restrooms are available.
Here is a map of the first floor of Doe Library with restrooms and the accessible entrance marked, from BIDS:
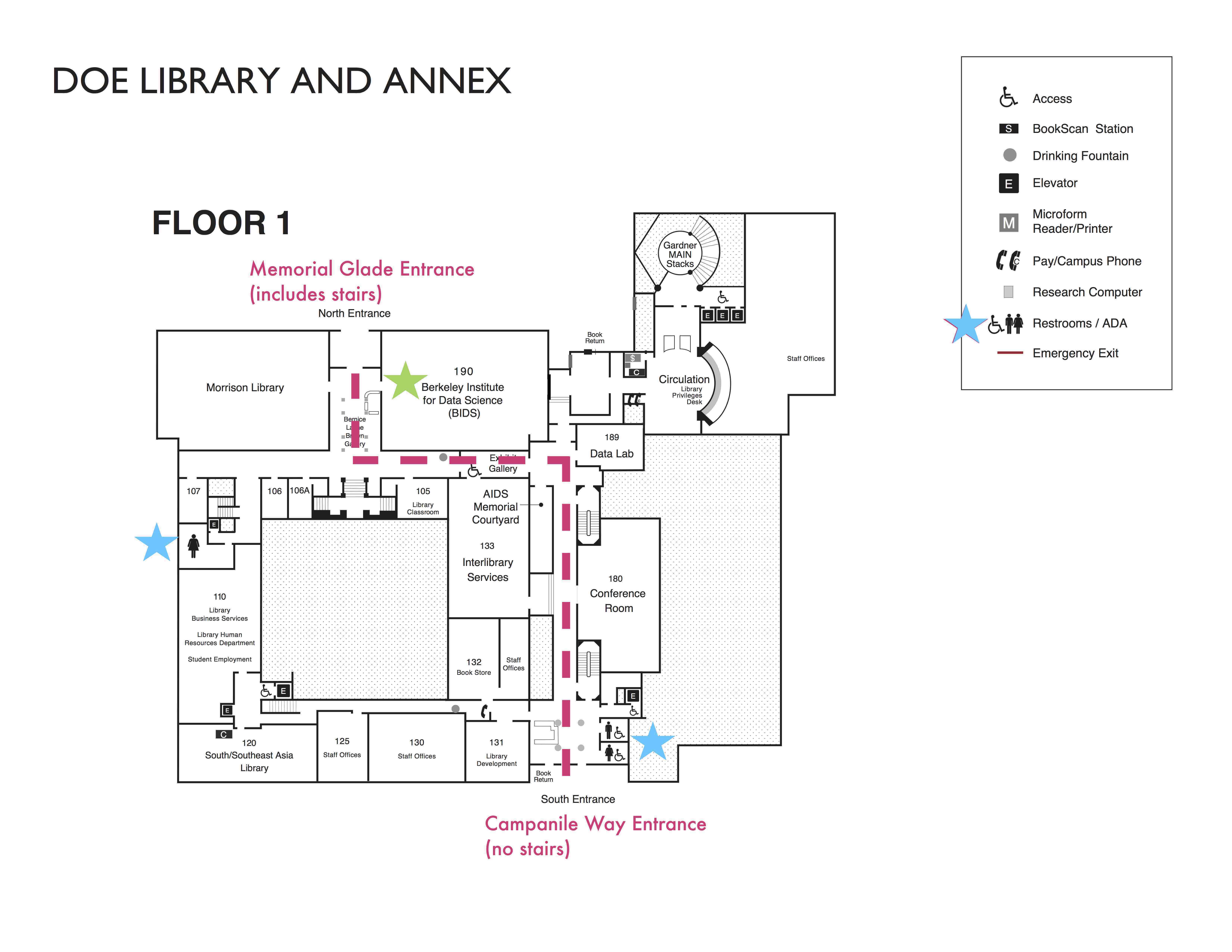
Materials will be provided in advance of the workshop and large-print handouts are available if needed by notifying the organizers in advance. If we can help making learning easier for you (e.g. sign-language interpreters, lactation facilities) please get in touch (using contact details below) and we will attempt to provide them.
Contact: Please email cypranowska@gmail.com or diyadas@berkeley.edu for more information.
Schedule (work in progress)
Surveys
Please be sure to complete these surveys before and after the workshop.
Day 1
| 9:30 am | Introduction to Data Carpentry |
| 10:00 am | Genomics Organization |
| 11:15 am | Coffee break |
| 11:30 am | Genomics with the Shell |
| 1:00 pm | Lunch break (on your own) |
| 2:00 pm | Genomics with the Shell, cont'd |
| 3:30 pm | Coffee break |
| 3:45 pm | Genomics with the Shell, cont'd |
| 5:00 pm | Wrap up |
Day 2
| 9:30 am | Wrangling Genomics Data |
| 11:15 am | Coffee break |
| 11:30 am | Wrangling Genomics Data, cont'd |
| 1:00 pm | Lunch break (on your own) |
| 2:00 pm | Wrangling Genomics Data, cont'd |
| 3:00 pm | Data manipulation in R |
| 3:30 pm | Coffee break |
| 3:45 pm | Data manipulation in R, cont'd |
| 4:30 pm | Intro to using Savio |
| 5:30 pm | Wrap up |
Syllabus (work in progress)
Genomics Project Organization
- Data tidiness
- Planning NGS Projects
- Examining Data on NCBI SRA database
The Unix Shell
- Files and directories
- Pipes and redirection
- Creating and running shell scripts
- Organizing filesystems for bioinformatics projects
- Reference...
Wrangling Genomics Data
- Assessing Read Quality
- Trimming and Filtering Reads
- Variant Calling
- Automation
Programming in R for Genomics
- Working with data frames
- Using the dplyr package
- Data visualization
Setup
To participate in a Data Carpentry workshop, you will need access to the software described below. In addition, you will need an up-to-date web browser.
We maintain a list of common issues that occur during installation as a reference for instructors that may be useful on the Configuration Problems and Solutions wiki page.
Data
The data for this workshop can be accessed through an Amazon Machine Image or downloaded to your local machine, however the data are quite large. Basic instructions for launching a cloud instance can be found here, and instructions for using the AMI instance for this workshop can be found here.
To download the data locally use this link: https://osf.io/ycu8j/
Be aware these data are quite large (~51 GB). The data are organized into two directories:
- dc_sample_data (124K)
- .dc_sampledata_lite(51GB)
The Bash Shell
Bash is a commonly-used shell that gives you the power to do simple tasks more quickly.
Windows
Video Tutorial- Download the Git for Windows installer.
- Run the installer and follow the steps bellow:
- Click on "Next".
- Click on "Next".
- Keep "Use Git from the Windows Command Prompt" selected and click on "Next". If you forgot to do this programs that you need for the workshop will not work properly. If this happens rerun the installer and select the appropriate option.
- Click on "Next".
- Keep "Checkout Windows-style, commit Unix-style line endings" selected and click on "Next".
- Keep "Use Windows' default console window" selected and click on "Next".
- Click on "Install".
- Click on "Finish".
-
If your "HOME" environment variable is not set (or you don't know what this is):
- Open command prompt (Open Start Menu then type
cmdand press [Enter]) -
Type the following line into the command prompt window exactly as shown:
setx HOME "%USERPROFILE%" - Press [Enter], you should see
SUCCESS: Specified value was saved. - Quit command prompt by typing
exitthen pressing [Enter]
- Open command prompt (Open Start Menu then type
This will provide you with both Git and Bash in the Git Bash program.
macOS
The default shell in all versions of macOS is Bash, so no
need to install anything. You access Bash from the Terminal
(found in
/Applications/Utilities).
See the Git installation video tutorial
for an example on how to open the Terminal.
You may want to keep
Terminal in your dock for this workshop.
Linux
The default shell is usually Bash, but if your
machine is set up differently you can run it by opening a
terminal and typing bash. There is no need to
install anything.
Software
| Software | Install | Manual | Available for | Description |
|---|---|---|---|---|
| FastQC | Link | Link | Linux, MacOS, Windows | Quality control tool for high throughput sequence data. |
| Trimmomatic | Link | Link | Linux, MacOS, Windows | A flexible read trimming tool for Illumina NGS data. |
| BWA | Link | Link | Linux, MacOS | Mapping DNA sequences against reference genome. |
| SAMtools | Link | Link | Linux, MacOS | Utilities for manipulating alignments in the SAM format. |
| BCFtools | Link | Link | Linux, MacOS | Utilities for variant calling and manipulating VCFs and BCFs. |
| IGV | Link | Link | Linux, MacOS, Windows | Visualization and interactive exploration of large genomics datasets. |
Installing from the terminal
Most of these software packages can be installed using conda or brew. Instructions for installing from the command line (including from source) can be found here.
Text Editor
When you're writing code, it's nice to have a text editor that is
optimized for writing code, with features like automatic
color-coding of key words. The default text editor on macOS and
Linux is usually set to Vim, which is not famous for being
intuitive. if you accidentally find yourself stuck in it, try
typing the escape key, followed by :q! (colon, lower-case 'q',
exclamation mark), then hitting Return to return to the shell.
Windows
Video Tutorialnano is a basic editor and the default that instructors use in the workshop. To install it, download the Data Carpentry Windows installer and double click on the file to run it. This installer requires an active internet connection.
Others editors that you can use are Notepad++ or Sublime Text. Be aware that you must add its installation directory to your system path. Please ask your instructor to help you do this.
macOS
nano is a basic editor and the default that instructors use in the workshop. See the Git installation video tutorial for an example on how to open nano. It should be pre-installed.
Others editors that you can use are Text Wrangler or Sublime Text.
Linux
nano is a basic editor and the default that instructors use in the workshop. It should be pre-installed.
Others editors that you can use are Gedit, Kate or Sublime Text.
R
R is a programming language that is especially powerful for data exploration, visualization, and statistical analysis. To interact with R, we use RStudio.
Windows
Video TutorialInstall R by downloading and running this .exe file from CRAN. Also, please install the RStudio IDE. Note that if you have separate user and admin accounts, you should run the installers as administrator (right-click on .exe file and select "Run as administrator" instead of double-clicking). Otherwise problems may occur later, for example when installing R packages.
macOS
Video TutorialInstall R by downloading and running this .pkg file from CRAN. Also, please install the RStudio IDE.
Linux
You can download the binary files for your distribution
from CRAN. Or
you can use your package manager (e.g. for Debian/Ubuntu
run sudo apt-get install r-base and for Fedora run
sudo dnf install R). Also, please install the
RStudio IDE.